Speakers & researchers from



RL Actually Works. We'll Show You.
A 4-week intensive workshop. Train your own personal AI assistant with GRPO. Deploy RL in embodied AI and LLMs in production. Explore the frontier of RL research.
Phase 1 builds your RL foundations from scratch. Phase 2 throws you into real production projects.
MDPs, Bellman equations, value functions, exploration vs exploitation. Building intuition from first principles.
From tabular Q-learning to deep Q-networks. Experience replay, target networks, Double DQN, Dueling DQN, and Rainbow.
REINFORCE, advantage estimation (GAE), A2C/A3C. The policy gradient theorem and variance reduction.
Trust regions, clipped objectives, KL penalty. Why PPO is the backbone of RLHF. The full RLHF pipeline — reward modeling, PPO training, and alignment.
Group Relative Policy Optimization — the algorithm behind DeepSeek-R1. Online GRPO, Mini-batch GRPO, DAPO, and Dr. GRPO.
Direct Preference Optimization and its successors. SimPO's length-normalized formulation, IPO, KTO, ORPO.
RL for autonomous agents. DeepEyes for visual reasoning, SWE-RL for code generation, RLEF for multi-turn feedback. The frontier of RL + LLMs.
Distributed RL training with veRL and OpenRLHF. Multi-GPU GRPO, Ray integration, vLLM rollout workers, FSDP pipelines.
Building custom RL environments. Gymnasium, MetaDrive for driving, MuJoCo for robotics, Docker-based execution environments.
MetaDrive-Arena deep dive. PPO racing agents, multi-agent competition, ELO leaderboards, sim-to-real transfer.
DeepSWE + rLLM + R2E-Gym stack. RL-powered coding agents that fix real GitHub issues — 59% on SWE-Bench with pure RL.
Embodied RL for robotics. Humanoid walking, OpenClaw manipulation, SmolVLA for robot learning, sim-to-real transfer, and reward shaping.
IRIS world model — act in imagined environments. Latent dynamics, Dreamer architectures, model-based RL for sample efficiency.
Shipping RL systems. Reward hacking detection, safety constraints, evaluation pipelines, monitoring, RLHF/RLAIF stack.
Hands-on with the frameworks that power RL at scale.
Hybrid parallel RLHF training. Ray + FSDP integration.
PPO, DPO, GRPO with Ray + vLLM for 70B+ models.
Build and standardize custom RL environments.
Standard RL environment API. Farama Foundation.
Single-file RL implementations for understanding.
Reliable PyTorch RL. PPO, SAC, DQN.
Distributed multi-agent RL at scale.
Driving simulator. 1000+ FPS. Bullet physics.
Gold standard physics for robotics RL.
RL for language agents. GRPO/PPO + Ray + vLLM.
Every project ships a working system. These are the portfolio pieces that get you hired.
Train PPO agents for competitive 1v1 autonomous racing. Multi-agent environments, ELO leaderboard, sim-to-real transfer.
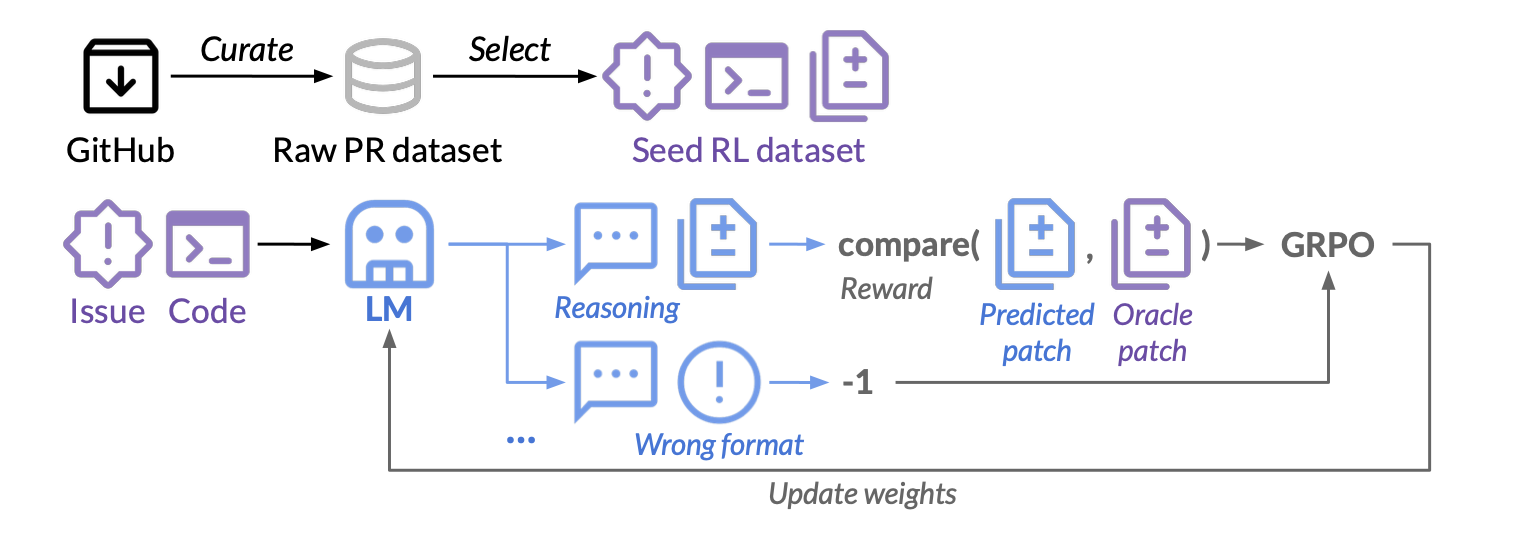
Build an RL-powered coding agent using DeepSWE + rLLM + R2E-Gym. Train on 8.1K real GitHub issues. Target: 59% on SWE-Bench Verified.
Build an open-source WhatsApp AI gateway trained with GRPO on your own conversations. Real-time dashboard, Process Reward Model scoring, asynchronous training on H100 GPUs via RunPod. The model improves while serving responses live.
Vision-Language-Action models for robotic control. RL-tuned inference — making small models perform like large ones through smart RL.
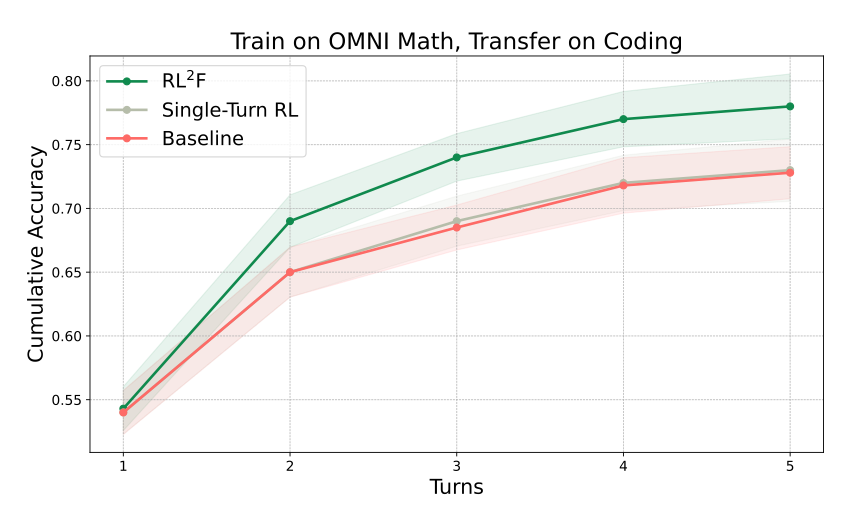
Implement the RL2F paper from Google DeepMind — a framework that treats in-context learning from feedback as a trainable skill. Build teacher-student didactic interactions, train with multi-turn RL, and reproduce the result where Gemini Flash nearly matches Gemini Pro on HardMath2. Achieve cross-domain generalization to ARC-AGI and Codeforces.
Train a simulated humanoid to walk using RL. Reward shaping, curriculum learning, MuJoCo environments, and locomotion policy transfer.
Implement the IRIS world model for imagination-based RL. Latent dynamics, generate training data from imagined trajectories, benchmark on Atari.
Reproduce CaP-X RL — the first framework to turn frontier LLMs into coding agents that control real robots. Build CaP-Gym (program-synthesis robot environment), benchmark VLMs on CaP-Bench, run CaP-Agent0 on real embodiments, and train CaP-RL with verifiable rewards for sim-to-real transfer with near-zero gap. Outperforms specialized VLA models on perturbed manipulation tasks.
You've trained models but never an RL agent. Understand PPO, GRPO, and the RLHF stack powering LLM alignment.
You know the theory but haven't shipped production RL. Bridge the gap between papers and real systems.
Interviewing at OpenAI, DeepMind, Anthropic, NVIDIA? RL systems knowledge is the differentiator.
You build hardware. Now train the brains. Sim-to-real, humanoid locomotion, dexterous manipulation.
Understand the RL layer — RLHF, DPO, GRPO — that turns base models into aligned systems.
Research roadmaps, paper reading lists, and mentorship to get your first RL paper published.
Read our research and explainers on Substack before the workshop begins.
Why Reinforcement Learning will dominate the next phase of AI intelligence. The transition from isolated interactions to continuous learning streams.
Read on Substack →How humans built AI models that reason. Inference-time compute, pure RL, supervised fine-tuning + RL, and distillation — from ChatGPT to DeepSeek-R1.
Read on Substack →A beginner's guide to RLHF. Reward modeling, policy gradients, PPO — with practical implementations from fine-tuning GPT-2 to text summarization.
Read on Substack →When Manning Publications needed an author for the RL chapter in their DeepSeek book, they came to Vizuara. That's the depth of expertise behind this workshop.

Dr. Rajat Dandekar authored the reinforcement learning chapter in Manning's DeepSeek book — covering the algorithms, training pipelines, and production techniques that power state-of-the-art reasoning models.
This isn't a team that learned RL from tutorials. Vizuara has the research depth to write the textbook and the engineering experience to ship production systems. When you enroll in this workshop, you're learning from the people publishers trust to explain RL to the world.
Co-founders of Vizuara AI Labs, bringing cutting-edge research to the classroom.
Industry insights from the frontier of AI research.
Guest speaker sessions are complimentary for all students enrolled in Phase 1 or Phase 2.

Dr. Dandekar has successfully taught the acclaimed "Reasoning LLM from Scratch" course, helping hundreds of students master complex AI concepts through practical, hands-on learning.
With extensive research experience in reinforcement learning and deep learning at top-tier institutions, Dr. Dandekar brings cutting-edge knowledge directly to the classroom. This workshop is born from the conviction that RL actually works — and the gap isn't in the algorithms, it's in knowing how to ship them.
Personalized research mentorship to help you publish your first RL paper and build a research career.
A custom research direction tailored to your interests and background in RL.
Bi-weekly sessions with Dr. Rajat Dandekar covering research, career, and publication strategy.
Curated reading lists, code templates, and guidance on writing your first research paper.
End-to-end support from idea to submission — venue selection, draft review, and rebuttal strategy.
Individual courses or bundles. Guest speaker sessions are complimentary for all Phase 1 & Phase 2 students.
🎉 Early-bird discount applied to all prices below — valid till April 25, 2026.
DQN, Policy Gradients, PPO, TRPO, GRPO, DPO, SimPO, Agentic RL. 7 lectures + labs.
8 capstone projects — racing agents, humanoid walking, agentic SWE, robotics coding agents, world models.
Personalized roadmap, curated reading list (12-15 papers), code template, draft outline.
Bi-weekly 1:1 with Dr. Rajat Dandekar. Research, career, publication support.
Phase 1 + Phase 2 + Research Starter Kit + RL Research Mentorship
Phase 1 + Phase 2
Phase 1 + Research Starter Kit + RL Research Mentorship
Phase 1 + Phase 2 + RL Research Mentorship
Phase 2 + Research Starter Kit + RL Research Mentorship
Phase 1 + Phase 2 + Research Starter Kit
Phase 1 + RL Research Mentorship
Phase 2 + RL Research Mentorship
Phase 1 + Research Starter Kit
Phase 2 + Research Starter Kit
EMI available · Lifetime recording access

